
Projects
Tabletop Games Framework (TAG)
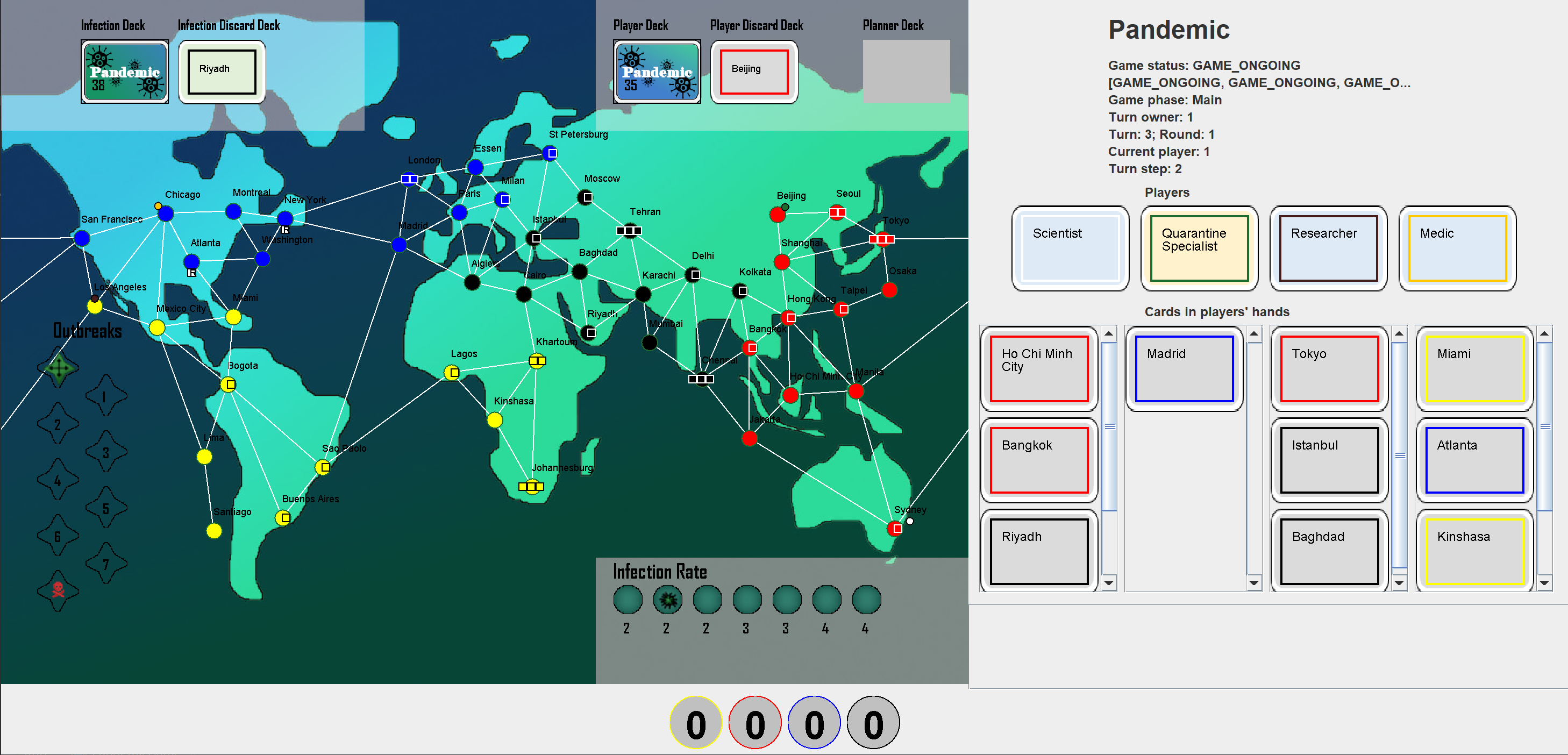
The Tabletop Games Framework (TAG) is a Java-based benchmark for developing modern board games for AI research. TAG provides a common skeleton for implementing tabletop games based on a common API for AI agents, a set of components and classes to easily add new games and an import module for defining data in JSON format. At present, this platform includes the implementation of seven different tabletop games that can also be used as an example for further development. Additionally, TAG also incorporates logging functionality that allows the user to perform a detailed analysis of the game, in terms of action space, branching factor, hidden information, and other measures of interest for Game AI research. You can find the repository here and the paper that describes the design here
PyTAG
PyTAG is a Python interface for the Tabletop Games framework. PyTAG was created with the intent to bridge the gap between the tools available in Python for Reinforcement Learning and the games implemented in TAG. Tabletop games bring various challenges to RL agents compared to search-based agents, such as complex action spaces, unique observation spaces (various embeddings), multi-agent dynamics with competitive and collaborative aspects, and lots of hidden information and stochasticity. PyTAG is available on Github.
Java-pommerman

I was involved in creating the Java version of the Pommerman framework. The framework is available here. We also evaluated Statistical Forward Planning methods in the framework, you can read the paper here. The screenshot from the game’s GUI is on the right.
Game parameter search using MAP-elites
We used a simple game called CaveSwing to tune the game’s hyper-parameters using the MAP-Elites algorithm. Using MAP-elites we could find levels that the agent played with different behaviours. The heatmap below shows the result of a run of MAP-elites when observing the average height the agent takes to solve the level in combination with the average speed the agent takes to finish the level. The code is available on GitHub.

Grapple Battle
As part of the first-year training in IGGI, we had to design and develop a game using Unity in a week. We came up with a First-person, split-screen game where the players have to grapple to avoid falling into the lava. The game features multiple weapon types and game modes: Capture the flag and deathmatch. You can check the gameplay in the video below: